Paperless-AI: KI-gestützte Dokumentenverwaltung für Paperless-ngx
![]() von Olli | 21 Kommentare
von Olli | 21 Kommentare
Das papierlose Büro kann man heutzutage mit etlichen Tools erreichen, Paperless-ngx ist eines davon. Doch es ist nicht immer alles Gold, was glänzt. Die manuelle Verschlagwortung und Kategorisierung von Dokumenten kann ordentlich Zeit in Anspruch nehmen. Mit dem OpenSource-Tool Paperless-AI gibt es eine spannende Lösung, die künstliche Intelligenz in den Dokumenten-Workflow integriert.
Die als Docker-Container bereitgestellte Erweiterung analysiert neue Dokumente automatisch und extrahiert wichtige Informationen wie Absender, relevante Tags und sinnvolle Titel. Dabei habt ihr die Wahl zwischen der OpenAI API oder lokalen Modellen wie Mistral, Llama, Phi 3 oder Gemma 2 via Ollama – besonders interessant für alle, die ihre Dokumente nicht in die Cloud schicken möchten. Logisch: Wer auf lokale Modelle setzt, sollte entsprechende Rechenpower bereitstellen. Mittlerweile entpuppt sich da der Basis-Mac-Mini als echte Alternative für den Heimserver – natürlich, nur wenn man mehr macht als Pihole etc.
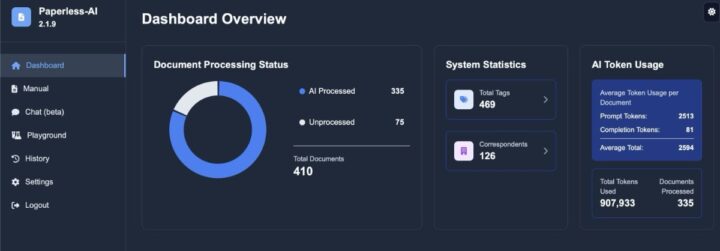
Die Einrichtung gestaltet sich dank Docker sehr einfach. Nach dem Start erreicht ihr die moderne Weboberfläche über Port 3000. Hier wartet ein übersichtliches Dashboard, das euch den Status der Dokumentenverarbeitung, Systemstatistiken und die KI-Token-Nutzung anzeigt. Die gesamte Konfiguration erfolgt über die Setup-Oberfläche, wo ihr die Verbindung zu Paperless-ngx einrichtet (dazu benötigt ihr den Paperless-API-Token aus eurem Profil, die URL und Co.) und das gewünschte KI-Modell auswählt.
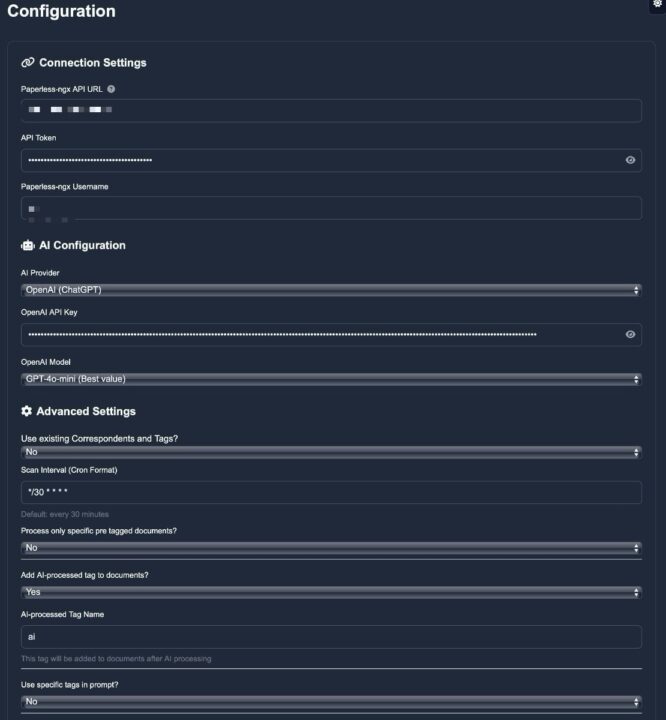
Ihr könnt festlegen, wie oft nach neuen Dokumenten gesucht werden soll und ob die KI nur bestimmte Dokumente verarbeiten soll. Auch die Erstellung neuer Tags kann eingeschränkt werden. Verarbeitete Dokumente werden auf Wunsch automatisch mit einem speziellen AI-Tag markiert. Dazu könnt ihr der AI verklickern, wie sie sich verhalten soll. Das sieht bei mir so aus:
You are a personalized document analyzer. Your task is to analyze documents and extract relevant information.
Analyze the document content and extract the following information into a structured JSON object:
1. title: Create a concise, meaningful title for the document
2. correspondent: Identify the sender/institution but do not include addresses
3. tags: Select up to 6 relevant thematic tags
4. document_date: Extract the document date (format: DD-MM-YYYY)
5. language: Determine the document language (e.g. „de“ or „en“)Important rules for the analysis:
For tags:
– FIRST check the existing tags before suggesting new ones
– Use only relevant categories
– Maximum 4 tags per document, less if sufficient (at least 1)
– Avoid generic or too specific tags
– Use only the most important information for tag creation
– The output language is the one used in the document! IMPORTANT!For the title:
– Short and concise, NO ADDRESSES
– Contains the most important identification features
– For invoices/orders, mention invoice/order number if available
– The output language is the one used in the document! IMPORTANT!For the correspondent:
– Identify the sender or institution
– When generating the correspondent, always create the shortest possible form of the company name (e.g. „Amazon“ instead of „Amazon EU SARL, German branch“)For the document date:
– Extract the date of the document
– Use the format YYYY-MM-DD
– If multiple dates are present, use the most relevant oneFor the language:
– Determine the document language
– Use language codes like „de“ for German or „en“ for English
– If the language is not clear, use „und“ as a placeholder
Neben der automatischen Verarbeitung bietet Paperless-AI auch eine manuelle Analyse-Funktion. Hier könnt ihr einzelne Dokumente gezielt von der KI analysieren lassen und die Vorschläge vor der Übernahme prüfen. Eine weitere Funktion ist der integrierte Chat: Hier beantwortet die KI Fragen zu euren Dokumenten, die in Paperless hinterlegt – praktisch, wenn ihr bestimmte Informationen sucht oder Zusammenhänge verstehen wollt. Ob man das am Ende wirklich nutzt, muss jeder selbst durchdenken.

Für Administratoren gibt es ein Debug-Interface unter /debug, das bei der Fehlersuche hilft. Das System überwacht sich zudem selbst und startet bei Problemen automatisch neu. Eure Einstellungen und Verarbeitungsdaten werden in einer lokalen Datenbank gespeichert, die sich bei Bedarf ebenfalls sichern lässt.
Wichtig: Da Paperless-AI direkte Änderungen an euren Dokumenten in Paperless-ngx vornimmt, solltet ihr vor dem ersten Einsatz unbedingt ein Backup erstellen. Kann ja immer mal was schiefgehen.
Die Erweiterung überzeugt durch ihre durchdachten Features und die einfache Integration. Besonders für größere Dokumentensammlungen kann sie den Verwaltungsaufwand deutlich reduzieren. Die Wahlmöglichkeit zwischen Cloud- und lokaler KI macht das Tool dabei für verschiedene Anforderungen interessant. Solltet ihr paperless-ngx nutzen, dann schaut ruhig mal rein.
| # | Vorschau | Produkt | Preis | |
|---|---|---|---|---|
| 1 |

|
Synology DS223J 2 Bay Desktop NAS, weiß |
192,00 EUR |
Bei Amazon ansehen |
| 2 |

|
Synology Diskstation DS124 NAS System |
149,90 EUR |
Bei Amazon ansehen |
| 3 |
|
Synology DS223j 2-Bay Diskstation NAS (Realtek RTD1619B 4-Core 1.7 GHz 1GB DDR4 Ram 1xRJ-45 1GbE... | 437,00 EUR | Bei Amazon ansehen |
Transparenz: In diesem Artikel sind Partnerlinks enthalten. Durch einen Klick darauf gelangt ihr direkt zum Anbieter. Solltet ihr euch dort für einen Kauf entscheiden, erhalten wir eine kleine Provision. Für euch ändert sich am Preis nichts. Partnerlinks haben keinerlei Einfluss auf unsere Berichterstattung.










Interessant, automatische Datensortierung sollte standardmäßig in macOS integriert sein statt dieser unnötigen AI Spielereien in der Notes app.
Wie genau kommst du darauf, dass dieser Artikel irgendetwas mit MacOS oder der Notes App zu tun hat?
Frag ich mich auch gerade xD
Ich habe Paperless-AI ausprobiert und bin nicht überzeugt. Zumindest mein Stand von vor 3 Wochen ist, dass der Prozess quasi automatisch erfolgt. Man vergibt den Tag und muss dann mit dem Ergebnis leben. Da kommen dann auch neue und ganz kuriose und teils viel zu sehr ins Detail gehende Tags raus, mit denen man nichts anfangen kann. Und das obwohl man dem Prompt angibt, es soll keine neuen Tags erschaffen.
Daneben gibt es noch das Projekt „Paperless-GPT“, welches das Thema wesentlich eleganter löst und auch via Docker installiert wird. Alle mit Tags versehenen Dokumente werden dort angezeigt und Vorschläge gemacht. Außerdem kann man einstellen, ob neue Tags vergeben werden oder ob vorhandene verwendet werden.
Paperless-GPT Scheint aber von diesem Projekt hier, was die Entwicklung angeht aber ziemlich überholt zu sein. Ich hab es mir leider nicht angeschaut. Aber vielleicht findest du nochmal Zeit dir die, gefühlt 30, changelogs anzuschauen seit den drei Wochen. Würde mich freuen nochmal eine Einschätzung zu bekommen welches Tool besser ist.
Genau das kann Paperless-AI auch mit dem Manual mode und dafür noch so vieles mehr.
Paperless-GPT ist komplett überholt.
Schau dir mal die aktuellste Version an. Der Entwickler ist mit einer der aktivsten Maintainer den ich bisher so gesehen habe. Richtiges Herzensprojekt.
Hi Peter,
der Fokus von Paperless-GPT ist mehr auf LLM basiertem OCR + Metadata.
In diesem Artikel habe ich die Unterschiede zu Paperless-AI erklärt:
https://www.reddit.com/r/selfhosted/comments/1hxediz/paperlessgpt_yet_another_paperlessngx_ai/
Ich kann auf jeden Fall bestätigen, dass die Entwicklung von Paperless-AI super schnell vorangeht. Tolles Projekt!
Grüße vom Paperless-GPT Entwickler 😉
Verstehe nicht wofür das wirklich gut sein soll. Paperless-ngx hat doch eine Volltextsuche dabei, sobald man mehrere Begriffe im Suchfeld eingibt und auf Erweiterte Suche umschaltet werden doch alle Dokumente mit den passenden Wörtern sehr schnell gefunden. Damit kann man auch ganz schnell Dokumenten nochmals zusätzliche Tags geben, die man vielleicht am Anfang noch nicht hatte. Mit zu vielen Schlagwörtern/Tags kann man sich auch selbst das Leben schwer machen. Auch ohne Ki habe ich bis jetzt immer sehr schnell die Dokumente gefunden die ich gesucht habe, es sei denn ich habe diese vergessen einzuscannen 🙁
Steht doch oben, wofür das gut sein soll.
Ich nutze, wie in meinem anderen Kommentar geschrieben, Paperless-GPT. Damit kann man auch automatisch Titel generieren lassen und spart sich somit auch diese 10 Sekunden pro Dokument.
Solange AI eher Ich-denke-mir-irgendwas-aus Programme sind, lasse ich sowas bestimmt nicht an meine wichtigen Dokumente ran. ich will mich später schließlich auf sie verlassen können.
Ich verstehe nicht, warum das Tool die Originaldokumente verändert bzw. verändern muss. Das leuchtet mir vom Prozess her nicht ein und ich halte es für eine Dokumentenverwaltung auch nicht für sinnvoll. Die Metadaten klingen teilweise spannend, vor allem die Kategorisierung. Aktuell arbeite ich noch mit per OCR erkannten Dokumenten und suche mit Copernic im Bestand. Aber eben in unkategorisierten Daten. Ich kann mir da noch viel vorstellen. Zum Beispiel, dass die KI Dokumente nach Todos und Fälligkeiten durchsucht und diese automatisch im Kalender bzw. in der Todo-Liste einstellt. Oder verwirrende Schreiben in verständlicher Sprache zusammenfasst. 😉
Der Satz hat mich auch etwas stutzig gemacht. Könnte es vielleicht ein Missverständnis sein? Paperless NGX ändert ja generell nichts an den Originaldokumenten und Paperless AI greift über Paperless NGX auf die Dokumente zu. Ich denke hier sind eher die bereits vergebenen Tags gemeint, die von der KI evtl. überschrieben werden.
Hallo!
Ich interessiere mich auch für Paperless-ngx und habe ein Synology-NAS, auf dem dies installiert werden könnte. Ich habe mir dazu auch einige Videos, z.B. zur Installation von Docker angesehen, aber das überschreitet meine laienhaften Kenntnisse.
Hat jemand eine Idee, wie ich eine professionelle IT-Firma finden könnte, wo ich mit meiner NAS hinfahren und die mir dann sowohl Docker, als auch Paperless-ngx installieren können?
Vielen Dank für einen Tipp
Ich weiß jetzt nicht, welches Synology-Modell du genau verwendest oder in welcher Gegend du lebst, aber eigentlich ist die Installation von Docker nicht komplizierter als die Installation von Software auf einem PC…
Selbst wenn du eine IT Firma findest, die das für dich übernimmt: Du solltest dich darauf gefasst machen, dass bei Updates der Docker-Container es auch mal zu kleineren Problemen kommen kann (kann!), die ein manuelles Eingreifen erfordern. Was man außerdem nicht vergessen sollte: Ein ordentliches Backup davon (nicht auf dem NAS, auf dem der Container läuft), damit im Falle der Fälle kein Datenverlust auftreten kann…
Schau mal hier bei Marius.
Damit bekommst Du es hin: https://mariushosting.com/synology-install-paperless-ngx-with-office-files-support/
Vielen Dank! Das schaut auf den ersten Blick schon einmal gut aus und ich werde mich in den nächsten Tagen mal daran setzen und es versuchen
Hat jemand einen Tipp, wie ich an der Fehlermeldung „OpenAI API Key is not valid. Please check the key.“ vorbei komme? Danke
? Entweder du hast eine lokale AI installiert oder du hast einen api key von openai. Du kannst es nicht ohne ki starten, macht ja auch keinen Sinn. Hab mir für 5$ ein paar Token bei openai gekauft und es läuft wunderbar. Meine 600 Dokumente haben ca. 40 Cent verbraucht. Hab also noch genug übrig.
Soweit ich mich erinnere kann das mit deiner hinterlegten Zahlungsmethode zusammenhängen. Ich glaube man muss dann ein Zahlungslimit festlegen oder das Konto mit einem Betrag aufladen.
Danke!
Nachdem ich 5 USD aufgeladen habe, hat alles tadellos funktioniert. Wahnsinn… Korrespondenten und Tags klappt fast sehr gut. Mal mit GmbH, mal ohne. Aber das kann man ja alles von Hand korrigieren. Nur Dokumenttypen bleibt komplett leer.
Wie habt ihr das eingestellt? Ich habe in der Vergangenheit beim Typ bereits unterschieden, ob Rechnung/Information etc. Gibt es irgendwo unterschiedliche Einstellungen, die man sich zum Vergleich einmal anschauen kann?